
Reflexões sobre dados pessoais vs dados não pessoais
Reflexões sobre dados pessoais vs dados não pessoais

Este artigo foi escrito para o Medium do Berkman Klein Center, da Universidade de Harvard, em 2019. O original, em inglês, está no Medium.
Existem oportunidades para coletar dados de fontes que não estão sendo consideradas dentro de conversas sobre governo digital. A separação de dados pessoais dos dados não pessoais está em debate, mas enquanto isso, empresas lucram com informações estratégicas que estão fechadas em silos, mas poderiam ser considerados dados públicos.
Tenho pensado muito sobre como o governo ou reguladores podem pensar sobre privacidade e economia de dados antes mesmo de desenvolver qualquer requisitos para sistemas, assumindo que as leis darão novos parâmetros para o desenvolvimento de aplicações. Alguns sistemas coletam dados sensíveis, pessoais e críticos, e é justo que tais dados sejam protegidos ao máximo de acessos indevidos ou não-supervisionados. Porém, outros sistemas coletam e consomem dados que não estão relacionados a nenhum usuário - mas ainda assim os afetam, e esses dados podem estar gerando novas ideias, tanto para políticas públicas quanto para negócios locais.
Muitos esforços dentro dos governos têm sido feitos para coletar todos os dados possíveis, incorporados em projetos que veem os dados como um valor inquestionável, mas deixando para trás 1) considerações sobre a privacidade dos cidadãos (e subsequentes direitos humanos); 2) custos para manter armazenamentos de dados a longo prazo, ou mesmo 3) custos para manter dados pessoais seguros e livres de atividades predatórias. Entendo que esses esforços são justos, mas o foco em dados pessoais talvez possa ser substituído, em parte, por um esforço da administração pública na coleta de dados que não são pessoais, mas são estratégicos para países. É compreensível que os primeiros dispositivos a serem considerados como ferramentas de coleta de dados sejam os celulares, carros ou dispositivos inteligentes das pessoas que poderiam estar dentro das residências, uma vez que já estão lá, ainda que tecnologias mais baratas para coleta de dados possam ser incluídas nas conversas sobre sistemas para digital Governo. Porém, câmeras e microfones podem ser substituídos por tecnologias mais acessíveis, muitas vezes distantes dos usuários, considerando armazenamento e infraestrutura, proporcionando dados melhores e mais precisos, preservando a privacidade e os direitos humanos.
Mas qual seria uma maneira razoável de começar a pensar sobre a coleta de dados para sistemas governamentais se não considerarmos dados pessoais? Não podemos esperar pelos regulação, porque software se desenvolve mais rápido do que a legislação e onde há software, há coleta de dados.
Claro que tive que fazer uso de um diagrama de Venn para esboçar a ideia de que alguns dados podem ser mais baratos de coletar, e devem ser abertos por padrão, para criar um ecossistema onde o governo também fornece os dados, como uma plataforma.
Alguns outros tipos de dados não deveriam ser usados pelo governo de forma alguma, e ainda assim, regulamentados com fortes garantias para os usuários. O comércio eletrônico e as mídias sociais são exemplos desses dados tão sensíveis. Casas inteligentes, por exemplo, podem conter dados sobre o consumo de água, mas não devem ser usadas como em todos os casos, ou serem dados abertos sem a devida anonimização. Já dados não granulares, coletados em pontos gerais de distribuição, poderiam servir para uma Agência Federal disposta a supervisionar a gestão da água entre cidades, por exemplo.
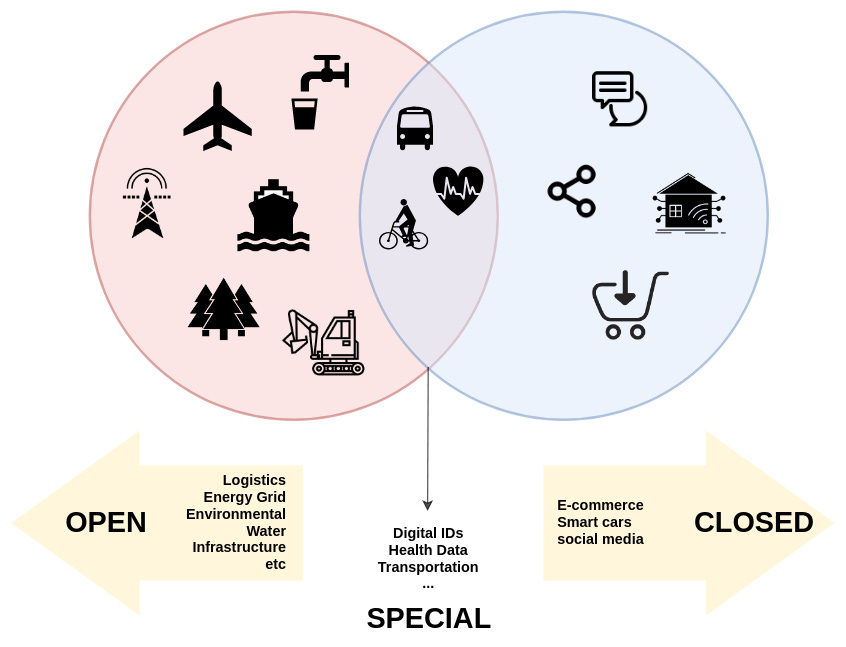
Poderíamos considerar uma categoria de “dados especiais” - dados pessoais gerenciados por sistemas públicos por padrão, como transporte, dados financeiros ou de saúde, que devem ter regulamentações fortes em vigor, com regras de interoperabilidade que sejam claras e debatidas com a sociedade como um todo.
Além disso, as regras de coleta de dados referentes à categoria especial precisariam do entendimento do usuário e do consentimento claro inserido na estrutura do sistema. Como exemplo, darei o link para a estrutura descrita por John Wilbanks e Stephen H Friend em seu artigo para a Nature chamado “Primeiro, projete para compartilhar os dados” (tradução livre de “First, design for data sharing”).
Claro que pode haver ceticismo sobre o uso de uma estrutura que classifique dados em setores antes mesmo de tais dados serem coletados. Afinal, já existem inúmeros tipos de classificações de dados e ontologias baseadas em data models definidos por engenheiros. Porém, todos os dias vejo casos em que soluções simples e baratas baseadas na separação setorial dos dados inspirada na gestão de políticas públicas são possíveis, como na gestão de barragens, evitando crimes ambientais como o que aconteceu no Brasil este ano, matando mais de 200 pessoas e um rio inteiro. Outro exemplo são os dados sobre infraestrutura, obtidos de formas não ortodoxas, como laser ou sonar, por exemplo, que devem ser fortemente considerados como prioritários para uma estratégia governamental de dados. Os governos estão construindo sua infraestrutura digital - o arranjo que apoiará a soberania e a capacidade de gestão de recursos em um futuro próximo, (que pode até já estar em vigor), e a utilização de dados pessoais potencializa o autoritarismo e arrisca a privacidade dos cidadãos, um direito fundamental. Encontrar alternativas em dados para a gestão pública é uma estratégia de mitigar riscos e agregar sustentabilidade às atividades do governo, deixando os dados pessoais para que sejam tratados caso a caso, com a devida atenção que merecem.